Рыбалка

Недавно завирусилась история о том, как кандидат вписал себе в резюме фиктивных два года опыта и прошел интервью на позицию в ИТ-компанию. Правда потом об этом узнали, и его вроде как уволили. Я не придал этому значения, пока мне не рассказали, что в одной онлайн-школе этому прям учат студентов, такая вот "гарантия трудоустройства". А на днях в одном из hr-чатов выложили фейковое резюме тестировщицы с 2 годами опыта, которая не смогла ответить ни на один технический вопрос.
В общем, весь этот треш оказался ближе, чем кажется. Не буду рассказывать, что обманывать нехорошо. Но я обратился за рекомендациями к Оле - HR в ИТ, карьерному консультанту и автору канала про карьеру, с которой мы трудоустроили уже ни один поток моих учеников.
Далее от ее лица.
Итак, последствия таких обманов могут быть разными:
(1) резюме могут закинуть по разным чатам и потом, чтобы найти работу, придется менять еще и фамилию (внутри одной сферы обычно тесно общаются и репутация дорога)
(2) в крупных компаниях есть службы безопасности, которые проверяют биографию еще до трудоустройства.
(у меня, кстати, был случай, когда клиентке отказали на последнем этапе из-за того, что данные из анкеты не совпали с реальностью)
(3) даже если все получилось, но в процессе работы информация вскрылась, могут и скорее всего уволят.
!(4) и что-то новенькое: hh.ru, на котором размещаются резюме, начал проверять точность информации и связываться с работодателями.
Поэтому поговорим о том, как можно привлечь внимание к себе, чтобы потом не уволили, как в этом случае:
(1) Начинать искать как можно раньше (когда изучена уже какая-то база), потому что то, что дают на курсах не всегда равно требованиям компаний. Чем больше смотрите вакансии и общаетесь, тем лучше понимаете, что нужно рынку.
(2) Использовать нетворкинг - знакомиться с людьми, которые работают в тех компаниях, куда вы хотите. Даже просто написать и попросить зарефералить. Теория с рукопожатиями тоже работает (у меня так много клиентов и знакомых нашли работу)
*кстати, консультант тут тоже обычно помогает и закидывает резюме по своим каналам (это, конечно, не гарантия успеха, но повышает конверсию)
(3) Резюме должно быть продумано до мелочей, из самого базового:
➡️ название должности должно соответствовать названиям вакансий, т.е не "специалист", а максимально конкретно;
➡️на первом месте должен быть опыт по той вакансии, на которую вы хотите, даже если это учебный опыт;
➡️ расписать подробно навыки, которые вы получили на обучении, лучше сразу с примерами из практики.
(4) Брать из предыдущего опыта все навыки, которые могут быть полезны. Смена направления — это не начинать с нуля, всегда есть переносимые навыки. Например, опыт ведения коммуникации и работа в команде, который есть у всех, и другие soft skills. Успех поиска 50/50 зависит от hard и soft skills.
(5) Использовать сопроводительные письма и писать вдумчивые отклики на позиции (спам-рассылка скорее всего не даст результата). А вот резюме + нормальное сопроводительное можно отправлять не только на hh, но и напрямую в компании, даже если вакансии нет, вас могут добавить в базу и написать позже.
*я всегда читаю, когда вижу, что человек постарался, а иногда даже даю обратную связь и помогаю скорректировать.
(6) Использовать разные источники поиска, в том числе рассматривать стажировки, после которых можно трудоустроиться (иногда это быстрее, чем искать вакансии).
Да, рынок очень поменялся за последние несколько лет, и все эти шаги объединяет активность и инициативность. Пробуйте разные гипотезы, потому что если не делать, то точно не получится. И пишите в комментариях, если нужен подробный разбор того, как правильно составлять резюме.
❕Сегодня хочу поговорить на очень спорную тему, я бы даже сказал философскую. Отчасти из-за нее, возникает очень много непонимания между коллегами, работающими в одном и том же (казалось бы) "АйТи", но почему-то имеющих очень разное представление о процессах разработки и о том, что каждая роль команды должна выполнять. Особенно это часто всплывает в моих постах на этом ресурсе, в комментариях - это такой хороший срез из разных уголков нашего отечественного IT.
И это большая тема для постов и для рассуждений. Но сегодня сосредоточимся на небольшой части этой темы, касающейся непосредственно системных аналитиков.
Давайте поговорим о том, какие есть подходы к написанию ТЗ и степени его проработки на примере описания тех же микросервисов\их методов.
❕Представим, что мы является системным аналитиком в команде и нам поставили задачу - реализовать личный кабинет пользователя.
Т.е. когда пользователь нажимает на какую-нибудь иконку профиля в приложении или там на кнопку "Профиль" - ему должна открываться экранная форма, в которой ему отрисовывается определенный набор полей и эти поля заполняются информацией. Также допустим, что у нас сам объект "Пользователь" уже есть в системе, атрибутивный состав понятен и нужно только реализовать процесс получения данных о пользователе на фронт по его идентификатору (ТЗ на фронт, на экранную форму и на интеграцию его с бэком опустим).
Какие есть варианты написания ТЗ для данной задачи?
1️⃣Самый минимальный уровень детализации. Это когда системный аналитик просто ставит задачу на разработку Джире (ну или в рамках небольшой страничке в конфлю\ворде, в зависимости от того, как принято) и в постановке этой задачи пишет что-то вроде "Требуется реализовать процесс получения данных о пользователе и передачу ее с бэка на фронт по REST-запросу. Со стороны фронта требуется создать новую экранную форму приложения - "Личный кабинет" или "Профиль пользователя". Со стороны бэка требуется реализовать новый метод, который будет использовать фронт для запроса информацию по пользователю (и, скорее всего, перечисляет набор полей, которые должны передаваться на фронт в формате "Фамилия", "Имя" и т.д.)". Усё
Я не утрирую - это один из вариантов реального "ТЗ" на эту задачу. Плюсом к этому может быть описан пользовательский сценарий в вольном формате или в формате UC (и то это будет в лучшем случае). Т.е. по сути в рамках такого процесса разработчик получает из полезной информации - только состав полей, передачу которых ему нужно реализовать по запросу с фронта, и то только их наименования.
2️⃣Вариант с немного лучшей детализацией. В этом формате системный аналитик уже пишет ТЗ в каком-либо формате, в рамках которого указывает, что: "Требуется реализовать новый метод GET /users/, указывает полноценно параметры, которые данный метод должен потреблять на вход и параметры, которые он должен отдавать на выходе." Плюс может описать, также как в предыдущем пункте, верхнеуровневый сценарий взаимодействия с этим методом.
Уже чуть лучше и чуть больше полезной информации для разработчика, правда?
3️⃣Вариант с достойной реализацией. Этот вариант обычно используется на большинстве проектов ФинТеховских и я считаю его достаточным для того, чтобы написать хорошее, качественное ТЗ и разгрузить разработчика так, чтобы он не думал о деталях реализации, хотя бы алгоритмических и системных (то, к чему нужно стремиться со стороны СА, имхо).
В рамках этого варианта будет всё из предыдущих + будет полностью описана логика работы данного метода, как бизнесовая, так и техническая. Будут описаны все корнер-кейсы, правила обработки ошибок, варианты того, что может вернуться в ответе (кроме успешного ответа, еще и все варианты негативных). Логика может быть описана или на уровне псевдокода или просто словами - конкретно это уже не имеет значимой роли, главное то - что эта логика пошагово и подробно описана.
Пример подобного описания я приводил ранее в своих постах. Я топлю всегда как минимум за этот вариант описания любых задач - что бэковых, что фронтовых, любых. Избавить разработчиков от лишней работы с точки зрения проработки алгоритмов и логики, если мы вполне это можем сделать сами - у них хватает работы и так, можете поверить.
4️⃣Более полноценный вариант придумать не могу =)
Плюсом к 3 пункту дополнительно описывается еще и swagger-спецификация микросервиса в целом и конкретных эндпоинтов в частности. Кроме того, что это просто удобно, наглядно и очень детально - эту спецификацию разработчики могут использовать, чтобы сконвертировать ее напрямую в готовый код с расписанными классами и эндпоинтами, останется "только" докрутить бизнес-логику и метод готов (Тут просьба поправить меня коллегам, которые более глубоко погружены в разработку - так ли это или есть еще какие-то бенефиты для разработчиков. Могу в этом предложении быть не прав, пишу исходя из того, как мне это объясняли).
Кроме этого, такой подход хорошо использовать в парадигме swagger-first, особенно когда у вас есть насыщенный и активный процесс кросс-командной разработки. Отдать другой команде сваггер аналитику куда проще и быстрее, чем отдать полноценное ТЗ на сервис - хотя бы просто по времени. А большего им и не нужно (потому что им пофиг на то, как работает ваш сервис внутри, главное понять, как вас вызывать и что вы вернете в ответе).
А если это все еще и использовать в связке с asciidoc-документацией, выкладывании ее в git- ммм, сказка просто. Как вспоминаю об этих процессах, наворачивается скупая слеза ностальгии - как же это было здорово! Жаль, что я встретил это ровно в одном проекте, а во всех последующих так и не смог продавить внедрение чего-то похожего.
И я вполне понимаю почему (например, очень удобно когда ты почти не тратишь время и ресурсы на написание глубокого ТЗ - достаточно пары фраз, а дальше нехай разработчик разбирается. И чем дольше пишешь в таком режиме, тем больше он тебя поглощает). Но кроме этого есть и множество других, о чем поговорим в следующий раз.
А с какими процессами и подходами работаете вы?
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть огромное количество постов на тему софт-, хард-скиллов и про карьеру в целом - см. закрепленный дайджест.
Продолжаем список тем и вопросов, ответы на которые нужно знать, чтобы пройти собеседование на позицию джуниора.
Еще небольшое предисловие - судя по комментариям к предыдущему посту, не все понимают, что не обязательно, что ВСЕ эти вопросы попадутся вам одновременно. Это наиболее вероятные вопросы, которые вам зададут ( по крайней мере актуально для ФинТех сферы). Ну и опять же, всё очень зависит от интервьюера, его опыта и тех целей, которые ему поставило руководство компании\проекта, на интервью.
Есть еще очень хороший подход к интервью, когда ты задаешь вопросы по каждой теме, и чем больше правильных ответов дает соискатель - тем глубже ты копаешь в эту тему, пока его знания по вопросу не иссякнут. Это позволяет не просто прогнать человека по заданным темам, которые нужны компании, но и в целом представить его уровень более детально (плюс так куда интересней для всех участников собеса).
Более техническая часть собеса:
Архитектурно-интеграционные вопросы:
Что такое клиент-серверная архитектура? Что такое тонкий и толстый клиент, чем они отличаются? (Тут никто не ждет прям уверенных технических знаний и деталей реализации того или иного подхода, но в общих чертах знать нужно).
Что такое HTTP? Какие основные методы HTTP вы знаете? Какие функции они выполняют? Расскажите про структуру HTTP-сообщений. (Если вы перечислите основные методы и скажете, что у сообщения есть заголовок, строка и тело - это уже, в целом, неплохо. Если знаете больше этого, вообще замечательно).
Что такое REST? Какие основные принципы у него есть? Какие методы есть в REST? В чем разница между GET и POST запросом?
В каких местах (четырех) мы можем передать атрибуты в запросе? (Path, Body, Query, Header).
Что вы знаете про концепцию CRUD?
Что такое идемпотентность? Какие методы являются идемпотентными?
Что такое синхронные и асинхронные интеграции? В чем между ними разницы? С помощью чего можно их реализовать?
Можно ли реализовать асинхронную интеграцию через REST? (Вряд ли этот вопрос будут задавать, если вы не ответите на предыдущие. Это скорее со звездочкой и не обязательный)
Что такое очередь сообщений? Как передаются сообщения через очередь? Какие очереди сообщений есть и в чем между ними разница? (Если расскажете про PUSH/PULL-стратегии - плюсик в карму обеспечен)
Что такое гарантированная доставка сообщений и какими механизмами ее можно обеспечить?
Какие вообще способы интеграции существуют? С какими из них приходилось работать? В чем их преимущества и недостатки? (Интеграция через обмен файлами, через общую БД, через веб-сервисы и обмен сообщениями)
Базы данных:
Что такое базы данных? Какими они бывают? С каким БД приходилось работать?
Что такое ER-диаграммы? Приходилось ли их проектировать?
На какой уровень оцениваете свой уровень владения SQL? С какими инструментами по работе с БД знакомы?
Ну тут могут конечно и про формы нормализации спросить, но уже лишнее, как по мне. Я обычно спрашиваю больше про опыт проектирования БД в целом. Приходилось ли проектировать базу в целом и под конкретные задачи в частности, каким образом это было сделано.
Различные задачки:
Тут вообще кто во что горазд в плане придумывания задач. В среднем, вам дадут умозрительное задание на проектирование какой-либо системы и попросят выделить основные классы этой системы (возможно, предварительно нужно будет собрать требования с интервьюера), спроектировать интеграцию между частями этой системы/интеграцию с внешними системами (плюс объяснить выбор технологии интеграции). Основной упор на ваши размышления, в основном именно в подобных вопросах можно понять уровень соискателя, потому что все остальные можно заучить. А тут проверяется именно понимание того, о чем вы рассказывали предыдущую часть собеседования.
Небольшие оффтопные вопросы:
Расскажите, что такое авторизация, аутентификация и идентификация? Чем они отличаются друг от друга? (почему-то один из самых любимых вопросов некоторых людей)
Чем верификация отличается от валидации?
Приходилось ли работать с JIRA\Confluence?
Конечно, так получается, что если вы знаете ответы на все эти вопросы, или больше 80-90%, то как будто бы вы уже не джун. Но чем лучше вы отвечаете, чем лучше вы соответственно подготовились - тем больше вам зададут вопросов (в нормальном интервью, а не шаблонном). Что очень сильно повысит ваши шансы получить оффер и выделиться среди других кандидатов.
Поэтому, конечно, можно, и зачастую нужно, пробовать собеседоваться, при наличии знаний, которые позволят ответить вам на половину из этих вопросов - шансы всё еще будут, плюс вы получите опыт прохождения собеседований (что само по себе очень важно) и определите те темы, про которые часто спрашивают, но в которых вы пока еще не сильны.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть огромное количество постов на тему софт-,хард-скиллов и про карьеру в целом - см. закрепленный дайджест.
Любой вомбатолог на вопрос "В чем достоинство Вомбатов?" наверняка ответит - "В лапах!". И будет совершенно прав :)
Лапы Вомбата - механизм уникальный и не имеющий аналогов за рубежом. Своими лапами Вомбат умеет:
- извлекать из сумки фсякие предметы
- рыть тридцатиметровые (и глубже) норы
- чесать разнообразные части тела
- эротично ковыряться в носу
и многое, многое другое! Ж-)
Кроме того, лапами Вомбат стягивает фсе то , что плохо лежит и сидит (особенно на фигуре), а также фсе то что на первый взгляд хорошо запрятано и сныкано:)
Некоторые из вомбатовых лап заслуживают отдельного внимания.

Я немножечко забросила обзоры, но честное пионерское, когда вернусь с мотофеста - всё будет, вы меня знаете. Сейчас устала так, что даже моргать получается только в режиме моргнул-немного поспал. Нужен небольшой отпуск хотя бы на выходные, работать в режиме почти круглые сутки семь дней в неделю сложно, хоть и очень интересно.
Для тех, у кого есть вопросы - можно писать в телеграм @SexFox_1.
Это не канал, а просто средство связи.
Для тех, кто не хочет задавать вопросы в комментариях. Могу ответить не сразу, потому что иногда в два слова не уложишься, почти каждый ответ - развёрнутый и подробный. Его написать нужно сначала, а по ночам я вообще сплю иногда. Но это не точно. )
Мой канал в телеграм - SexFox.
Почему появился?
Потому что сотворить интересного на квадратный сантиметр времени у меня получается много, а писать посты - это вам не воробьям фигушки крутить. Да и достоин ли каждый шаг пусть и несравненной SexFox того, чтобы писать о нём пост? Если что - это сарказм.
Плюс там будут анонсы новых постов на Пикабу, мини-зарисовки из жизни секс-шопа, просто из жизни и всякое такое, что в посты не вошло. Думаю, что будут заметки типа "а смотрите чего красивого в секс-шопе появилось" без подробнейшего обзора, но если вызовет интерес - будет полноценный пост уже на Пикабу.
Ссылка на канал будет в шапке профиля, плюс бесить всех в конце постов (хе-хе).
Зачем появился?
Да чтобы интересно было (надеюсь) и на Пикабу оставить базу, а в телеге лапы разминать. Вы же мою продуктивность знаете.
Там пока только начало, заведён он только на днях, но зафлудить телеграм - за мной не заржавеет.

Всем привет.
Небольшое предисловие. Я осознаю, что этим постом я вступаю на охрененно тонкий лёд. Если уж к моему предыдущему посту были претензии за то, что я посмел использовать HTTP 404, то уже интересно, какие комментарии последуют после выхода этого поста, в любом случае - you are welcome!
Но тут стоит уточнить, что все те подходы (разные), по которым мы проектируем сервисы - они разные как раз потому, что нет единых mandatory правил к архитектуре приложений, которым если не следуешь - твоя система ломается и больше никогда в жизни не заработает, даже если ты исправишь ее. Есть лишь РЕКОМЕНДАЦИИ, а их многие интерпретируют по-разному и это тоже нормально. Для кого-то свойственно не использовать коды ошибок вообще и передавать их в теле ответа с HTTP 200, для кого-то нет. Ни один из этих подходов не является не правильным.
И нет никаких технических ограничений в принципе. Ты можешь спокойно использовать метод GET для удаления объекта, если ты его так напишешь (не делайте так) или использовать метод PUT, вместо POST, для создания объекта (так уже можно, если понимаешь почему). Главное, чтобы ты понимал как эти тонкости реализации правильно применять. Если сомневаешься - используй методы по классике, хуже от этого он работать не будет.
Да, можно уже прям сейчас кидать тапками.
Теперь уже к основному телу сабжа. Сейчас расскажу про ряд лучших практик, которые можно применять. @VRock, ты как раз спрашивал по поводу конвенции о наименовании ресурсов, тут про это тоже будет.
1. Имя endpoint'а - это существительное, а не глагол. Это одна из самых распространенных ошибок, которые я когда либо встречал (и сам совершал, естественно). Например, было в моей практике и такое - POST /generateMultipleDocument.
Тут важно понимать, что метод - это уже глагол и еще раз дублировать его в наименовании эндпоинта не нужно.
В идеале, в данном варианте будет POST /documents
Не везде от этого можно избавиться, но в большинстве случаев всё-таки можно, если потратить время на придумыванием вариантов (опять же - по факту нейминг ни на что, кроме красоты и структурированности вашего проекта не влияет. А на сколько это важно - решать вам или вашей команде).
1.1. Используйте множественное число. В большинстве случаев, при проектировании методов, работающих с вашим ресурсом - эти методы будут работать не с единственный экземпляром этого ресурса, поэтому название эндпоинта должно быть во множественном числе.
Если же нужно указать, что из всего массива экземпляров ресурса вам нужно получить\обновить\удалить какой-то конкретный, то помещайте идентификатор этого ресурса в URL, передавая его в path.
Например, вот так:
/documents
/documents/
Вместо:
/document
/document/
1.2. Используйте "/" для обозначения иерархии и в принципе используйте вложенность ресурсов.
Например, если мы именуем наш ресурс, как users//playlists//songs - это значит у мы хотим работать со всеми песнями, конкретного плейлиста конкретного пользователя. И сразу понятна иерархичность этих ресурсов.
1.3. Не используйте "/" как закрывающий символ вашего URI.
Вариант users//playlists//songs сильно лучше, чем users//playlists//songs/
1.4. Используйте "-" для разделения составных слов.
Заглавные буквы использовать нельзя, поэтому привычный lowCamelCase нам не подойдет. Если писать всё слитно - очень не читабельно.
Поэтому вместо /applications//creditcardhistory, куда лучше использовать /applications//credit-card-history.
2. Не забывайте про версионирование микросервиса. Почти любой сервис с течением времени развивается и обрастает все большим количеством функций. Если сервис при создании получил версию 1.0.0, то при добавлении какой-нибудь логики в него, добавлении нового метода или полного рефакторинга - версия должна измениться.
Например:
host/v2/documents вместо host/v1/documents после внесения мажорной доработки.
Основные правила версионирования - в случае, если меняется логика незначительно, не добавляется/изменяется обязательность атрибутов, то инкрементируется минорная версия.
В случае если был полный или частичный рефакторинг, менялись обязательные параметры (например, добавлен новый атрибут, который является обязательным), возможно при добавлении нового метода (тут вопрос к разработчикам, в этом случае тоже мажорная версия повышается или т.к. это не влияет на работу подписантов то пофиг?) - инкрементируется мажорная версия.
В этом случае, все подписанты (системы, использующие ваш сервис) вашего микросервиса должны в обязательном порядке переехать на новую версию вашего микросервиса, иначе они не смогут взаимодействовать с ним. Например, если вы добавили обязательный атрибут, то они будут получать в ответ на каждый запрос ошибку, если не доработаются и не начнут его передавать, что приведет к полной поломке этого процесса.
Однако, это не всегда обязательно - в случае, если появляется такая мажорная доработка, но ваши подписанты не готовы дорабатываться одновременно с вами (причин этому может быть множество) - вы можете выкатить одновременно две версии микросервиса, v1 и v2 и поддерживать их обе. Те, кто доработался будут использовать v2, остальные предыдущую версию. Это несет неудобства и затраты, но в любом случае лучше, чем допускать неработоспособность интеграции. В дальнейшем, когда все ваши подписанты доработаются - поддержку предыдущей версии можно остановить.
Примечание: структура версионирования такова: первая цифра - это мажор, вторая цифра - это минор, третья цифра - это патч. Про первые две я уже сказал, а последняя используется только разработчиками. Насколько я понимаю, она повышается вообще каждый раз когда вносят изменения в сервис, но тут могу быть не прав.
3. Используйте пагинацию.
Отправка большого объема данных на фронт, в ответ на его запрос о получении информации по массиву каких-либо объектов, не самая лучшая идея. Как минимум, если вернуть ему тысячи объектов, лежащих в базе и попадающих под выборку - он столько все равно не отобразит, но очень задумается.
Поэтому принято выполнять пагинацию таких данных (от слова page - страница), т.е. возвращать ему часть всей коллекции в каждом запросе. Например - 15, 30, 50 элементов + информацию о текущем положении полученной информации в общей выборке. Почитать про это можно более подробно где-нибудь тут (первая попавшаяся ссылка, я не вчитывался, не реклама).
4. Используйте коды ответов HTTP правильно и эффективно.
Их достаточно много (https://developer.mozilla.org/ru/docs/Web/HTTP/Status) и их можно использовать по назначению. Все знать и использовать не обязательно, но вот примеры их использования
Использовать 201 "Created", вместо 200 "OK", в случае если вы в POST действительно создаете какой-то ресурс. Используется только в POST (ну и в PUT, в ряде частных случаев).
Использовать 204 "No Content", вместо 200 "OK" для DELETE. Это ответ на успешный запрос и он не будет возвращать тело, что и не нужно для данного метода.
Не забывайте использовать 401 "Unauthorized", 403 "Forbidden" и 404 "Not found" вместо безликого 400 "Bad Request", когда это уместно. Как правило 400 кодом пользуются когда нужно ответить на какую-то ошибку валидации или в случае возникновения бизнесовой ошибки, которую вы заранее можете предсказать (очень настоятельно рекомендую хотя бы дополнять код ответа еще и кодом бизнесовой ошибки в этом случае и желательно ее текстом (error.code и error.message соответственно).
Для валидации желательно тоже).
А для всего остального можно и специальные коды использовать.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.
Всем привет.
UPD. Опять получился длиннопост с большим количеством текста в формате моих пояснений - простите, но не представляю как по-другому можно что-то объяснить, вроде стараюсь не графоманить.
В этом посте, наконец, приведу один из примеров того, как может быть написано техническое задание (кто-то может придраться, что это не ТЗ, а какой-то другой вид документа - да, возможно, но как-то сформировалась привычка для упрощения, что ТЗ - это любой документ, в котором описывается техническая постановка задачи, которую разработчик должен реализовать), в котором описываются требования к методу получения информации по конкретному объекту.
Шаблонов, на самом деле много и от команды к команде отличаются. Где-то СА просто пишут, что "метод должен получать объект User из базы Users и дальше отдавать его вызывающей стороне" - и это вся постановка. В каких-то командах упарываются и пишут ТЗ на микросервис целиком, в связке статьи в git в формате asciidoc + swagger (yes, I like it и отдельно про это тоже расскажу).
Но в большинстве случаев принято что-то среднее между этими крайностями - системному аналитику важно описать следующее:
То, какие данные метод получит на вход и правила валидации для них;
То, что метод должен сделать с этими данными, т.е. какую бизнес-логику выполнить;
То, что метод должен вернуть в ответ вызывающей стороне.
Допустим, нам нужно описать какой-нибудь метод, который получает любую бизнес-сущность по ее идентификатору.
Один из шаблонов, позволяющий это описать выглядит так (к сожалению, приходится скриншотом, потому что пикабу не умеет в таблицы (или я не умею в таблицы на пикабу)):
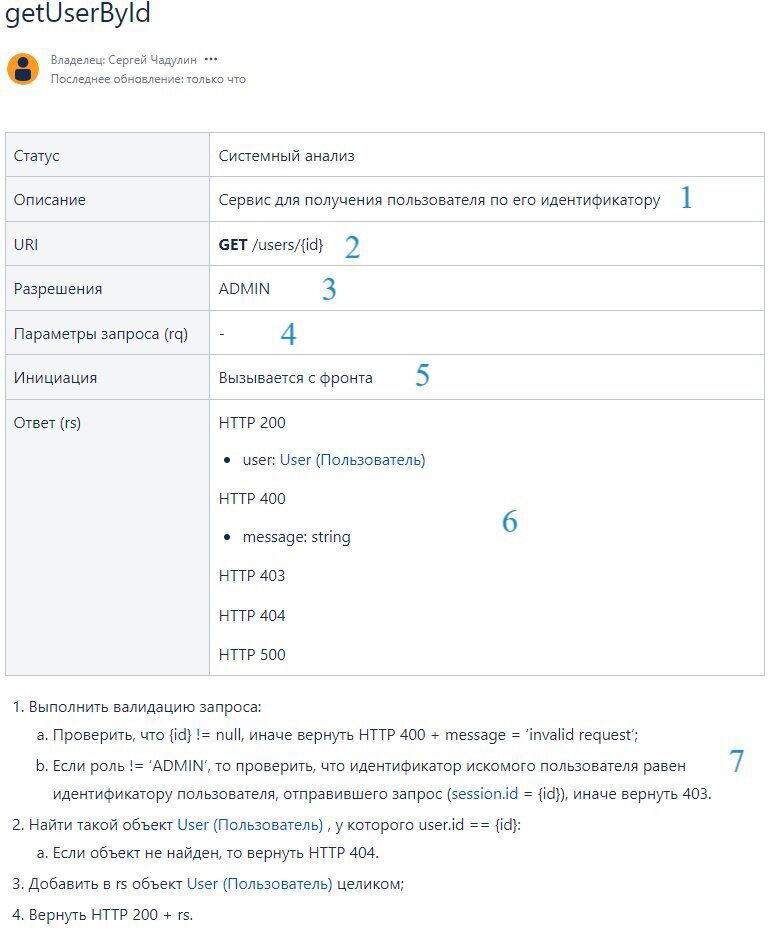
Если кто хочет посмотреть "вживую" или попользовать шаблон - вот ссылка на страницу моего конфлю (вроде должна работать).
Теперь по шагам:
Описание метода. Что он делает, для чего предназначен. Можно описать что-то конкретное, если сервис работает как-то специфично, такую краткую выжимку, что сторонним людям не приходилось анализировать его целиком;
URI или URL метода. Состоит из одного из типовых глаголов плюс сам путь, по которому данный метод будет доступен. Про всякие best practices нейминга расскажу отдельно, в комментариях под предыдущим постом спрашивали;
Разрешения или Permissions. Если у вас есть ролевая модель и вам нужно разграничить доступ к каким-либо ресурсам среди пользователей с разными ролями - то вступает в дело данная строка таблицы. В ней нужно перечислить те роли, у которых есть доступ до данного метода;
Параметры запроса, который должны (или могут) быть переданы на вход данного метода. Т.к. у нас очень простой метод, то у нас их нет. Единственный атрибут в виде идентификатора пользователя ( ) передается напрямую в ссылке. Т.е. пример запроса будет просто выглядеть вот так: GET /users/22 - дай мне пользователя с идентификатором 22.
Пункт больше для удобства, в случае, если у вас большая система и много взаимодействующих компонентов. Описываете, кто будет дергать ваши метод. Как минимум это нужно для того, чтобы потом, когда вы будете дорабатывать их - было понятно влияние. В данном случае, если вдруг метод поменяется мажорным образом, добавится какой-нибудь новый обязательный параметр - вы не забудете доработать еще и фронт.
Параметры ответа. Все варианты того, что ваш метод вернет вызывающей стороне после выполнения своей внутренней логики. Перечисляем как успешные коды ответа и всё их содержимое, так и ошибочные.
Непосредственно описание бизнес-логики метода. Т.е. что метод должен сделать с атрибутами, переданными на вход, и что должен вернуть.
Теперь немного про описание самой логики работы любого сервиса. Кому-то может показаться это сложным, но на самом деле все немного проще. Вам просто логически нужно представить у себя в голове, что должен вообще в принципе сделать ваш метод и попытаться придумать - как он должен это сделать.
На этом примере - у вас стоит бизнесовая задача (например): есть админка со списком пользователей, администратор нажимает на какую-то конкретную карточку пользователя, с целью просмотреть всю информацию по нему - в этот момент, как раз фронт откроет отдельную экранную форму и вызывает наш метод, передавая туда идентификатор искомого пользователя (который он ранее получил из другого метода, который получает массив пользователей, что-то вроде GET /users), чтобы получить всю нужную информацию для отображения.
Далее представляем что наш метод должен сделать, чтобы вернуть информацию по этому пользователю. Самое логичное - надо сначала найти его. Для этого нужно залезть в таблицу с пользователями и найти такого пользователя, у которого идентификатор будет совпадать с тем, что нам передали в запросе. Нашли - круто, не усложняем и возвращаем успешный успех фронт с передачей в теле ответа всей необходимой информации.
А что делать если не нашли? Вообще, технически такого быть не должно, потому что это значит, что у фронта устаревшая или недостоверная информация и нужно с этим разбираться - откуда он взял идентификатор, которого не существует? Но представим, что после того как админ открыл страницу со списком пользователей и до того, как перешел в карточку конкретного - другой админ удалил ее. В этом случае надо вернуть ошибку, что такой объект не найден.
Ну и всегда (по моему мнению), во всех методах нам нужно валидировать входящий запрос до того, как начать основную бизнес логику. Потому что зачем нам это делать и тратить драгоценное время и ресурсы, если мы заранее знаем, что запрос не валиден? Т.е. как минимум нам нужно проверить rq на соответствие контракту, что все обязательные атрибуты пришли и пришли в корректном формате. Как максимум выполнить еще всякие кастомные валидации, по типу тех же проверок на роли.
Также заранее поясняю, что в ответе ссылка на объект User (пользователь) ведет на описание атрибутивного состава объекта (в моем примере в конфлю нет, потому что я этого не сделал, но на боевых задачах - да), поэтому не нужно расписывать и дублировать этот объект еще и тут. Однако, если вам нужно передать не весь объект, а только его часть, например, не возвращать на фронт какие-то пароли пользователей или другие конфиденциальные данные, чтобы их не "схачили" - то нужно отдельно это указывать.
И еще поясню немного про пункт 1.b - особенно внимательные наверняка про него что-нибудь скажут. Пока писал, подумал, что можно использовать этот метод не только для админа, но и переиспользовать его на случай, когда обычный пользователь хочет получить информацию по себе же, например, когда открывает свой профиль. Вместо того, чтобы делать отдельный метод - просто разграничиваем права. Если он захочет запросить информацию о ком-то другом (если фронт подведет), то ему вернется болт.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.
Стоило только добавить волну профессий и титьки в игнор на неделю и вот результат 10 минут в горячем на Пикабу.
Грусть печаль(((
Всем привет.
Настала пора наконец закончить с прелюдиями и перейти к рассказу про один из самых важных навыков системного аналитика - REST. Больше важны навыки практического применения\проектирования, но и теория тоже важна. Как минимум для прохождения собеседования, потому что значительная часть вопросов приходится как раз на интеграцию и знание REST в том числе.
В следующем посте разбавлю серию только теоретических - практикой. Приведу шаблон того, как можно описывать API.
REST
Representational State Transfer (REST) в переводе — это передача состояния представления.
Сам по себе REST – это архитектурный стиль взаимодействия компонентов распределённого приложения в сети. Архитектурный стиль – это набор согласованных ограничений и принципов проектирования, позволяющий добиться определённых свойств системы.
И у него есть определенные принципы, которые важно понимать и применять при проектировании системы.
В рамках данного принципа самое важное - это отделение клиента и сервера. Клиент - это интерфейсная часть (уровень представления), сервер - это центральное звено системы, на котором реализованы все основные функции системы (наш backend). Более подробно рассмотрено в части 6 этой серии.
Это понятие означает, что сервер не должен хранить информацию о состоянии клиента, в том числе информацию о предыдущих запросах клиента, а клиент не должен знать ничего о текущем состоянии сервера.
Это не значит, что у них вообще нет состояния, но они не отслеживают состояние друг друга (что очень удобно, т.к. избавляет нас от необходимости держать постоянное неразрывное соединение между двумя системами).
Поэтому каждый запрос рассматривается индивидуально, как будто бы не было ничего до, и не будет после. Соответственно клиент в этом случае, обязан предоставить все необходимые данные для успешного выполнения запроса. Это, пожалуй, почти единственная логика, которая должна быть на клиенте.
Принцип гарантирует, что между клиентом и сервером существует общий язык (интерфейс), с помощью которого они будут понимать друг друга. Т.е. клиент посылает понятные серверу запросы, использую конкретные HTTP-методы, сервер посылает ответ в понятном клиенту формате.
Это достигается через несколько субограничений:
Идентификация ресурсов
В терминологии REST что угодно может быть ресурсом — HTML-документ, изображение, информация о конкретном пользователе - то, чему можно дать имя. Каждый ресурс должен быть уникально обозначен постоянным идентификатором. «Постоянный» означает, что идентификатор не изменится за время обмена данными, и даже когда изменится состояние ресурса. Если ресурсу присваивается другой идентификатор, сервер должен сообщить клиенту, что запрос был неудачным и дать ссылку на новый адрес.
Тут важно понимать, что в REST (в идеале, по крайней мере), ресурс может быть только существительным, а не глаголом. Потому что за "глагол", т.е. действие - отвечает конкретный метод.
2. Управление ресурсами через представления
Второе субограничение «унифицированного интерфейса» говорит, что клиент управляет ресурсами, направляя серверу представления, обычно в виде JSON-объекта, содержащего контент, который он хотел бы добавить, удалить или изменить. В REST у сервера полный контроль над ресурсами, и он отвечает за любые изменения.
Когда клиент хочет внести изменения в ресурсы, он посылает серверу представление того, каким он видит итоговый ресурс (а для этого, сервер сначала должен предоставить эту информацию клиенту). Сервер принимает запрос как предложение, но за ним всё так же остаётся полный контроль.
3. Самодостаточные сообщения
Самодостаточные сообщения — это ещё одно ограничение, которое гарантирует унифицированность интерфейса у клиентов и серверов. Только самодостаточное сообщение содержит всю информацию, которая необходима для понимания его получателем. В отдельной документации или другом сообщении не должно быть дополнительной информации.
В данных запроса должно быть указано, нужно ли кэшировать данные (сохранять в специальном буфере для частых запросов). Если такое указание есть, клиент получит право обращаться к этому буферу при необходимости.
Это нужно для того, что максимально ускорить обработку запроса от клиента. Для примера, если нам нужно часто получать информацию о пользователе (а сама информация о пользователе меняется достаточно редко, что важно), то мы можем закэшировать эту информацию.
Т.е. стандартный запрос выглядит условно так: Фронт -> микросервис адаптер к фронту -> какой-нибудь микросервис MDM системы пользователей -> база где лежат пользователи и потом обратный путь. Это не прям мгновенно всё происходит. Что мы делаем - например, наш фронт прислал запрос GET /user/121, мы проделали этот путь, описанный выше, но еще и сохранили эти данные в кэше на уровне микросервиса-адаптера. В следующий раз, когда фронт вызовет метод GET /user/121, наш путь будет намного короче и быстрее - всего лишь от фронта к нашему же микросервису в кэш и сразу обратно.
Тут есть множество нюансов, которые нужно учесть - но в целом полезный инструмент.
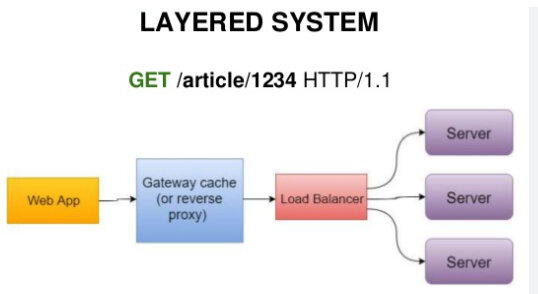
Система слоев предполагает наличие большего количества компонентов, чем клиент и сервер. В системе может быть больше одного слоя. Тем не менее, каждый компонент ограничен способностью видеть только соседний слой и взаимодействовать только с ним.
Но что самое замечательное, при добавлении новых слоев между клиентом и сервером - их не нужно дорабатывать. Т.е. не важно, если у нас архитектура выглядит как просто "Клиент" -> "Сервер", или "Клиент" -> "Прокси" -> "Балансировщик" -> "Несколько серверов" - их логика не меняется (тут разработчики могут меня поправить или дополнить, буду благодарен).
Что-то вроде того:
Еще есть отдельный принцип "Код по требованию", который подразумевает то, что клиент может получить с сервера прям "кусок кода" (условно), который ему необходимо выполнить у себя.
Звучит интересно, но честно, ни разу не сталкивался, поэтому не могу что-то детальное рассказать.
P.S.: В следующих постах расскажу про best practices, связанных с именованием эндпоинтов и прочими полезными штуками для проектирования своих апишек.
По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.
Всем привет.
В прошлом посте рассказал про HTTP в целом и много раз упоминал различные методы, но еще не рассказал что это такое - разбираемся.
Как я уже писал, метод - это название запроса, которое определяет то действие, которое будет совершаться в результате его выполнения.
Их всего 6 основных:
Метод GET предназначен для получения информации о каком-то конкретном ресурсе или массиве ресурсов. Он никак не изменяет эту информацию.
Похож на GET, но не возвращает тело ответа, а только стартовую строку и заголовки. Используется для получения метаданных, а также проверки и валидации ресурса.
Честно говоря - ни разу не приходилось использовать его на практике или даже просто видеть. Но могу предположить, что его можно использовать в том случае, когда нам нужно ткнуть какой-то ресурс палочкой и спросить - а ты вообще существуешь? Ну и, возможно, получить по нему какую-то метаинформацию.
Условно, можно вызвать HEAD /users/127 - мы получим в ответе HTTP 200, в том случае, если этот пользователь с идентификатором = 127 существует. И 404 - если нет.
Если же вызвать GET /users/127 - то мы получим HTTP 200 + тело ответа, в котором будет содержаться вся информации о пользователе с идентификатором 127 (ну тут смотря как реализовать, но по дефолту будет так).
Создает новый ресурс из переданных данных в запросе. Но это лишь по дефолту.
На самом деле POST самый универсальный метод и им возможно делать всё - и получать информацию, и создавать, и редактировать, и удалять, и запускать какие-то процессы. Тут важно понимать - почему именно так.
Например, мы можем использовать POST для поиска в том случае, если нам нужно зашифровать поисковые параметры в теле запроса, а не оставлять их в открытом виде в query-параметрах (прям в строке запроса). Либо использовать для поиска в том случае, если поисковых параметров слишком много и строка запроса получается слишком огромной - а у нее есть определенное ограничение по длине (очень больше, но всё-таки есть).
Можно использовать для запуска различных команд в оркеструющих микросервисах или коммандерах. Т.е. напрямую у нас никакой объект не создается, физических и лежащий в БД - но у нас создается (запускается) какой-нибудь бизнес-процесс.
Применений у этого метода очень много.
Изменяет содержимое ресурса по-указанному URI. PUT полностью заменяет существующую сущность.
Похож на PUT, но применяется только к фрагменту ресурса (заменяет точечно только часть ресурса)
Для понимания: Например, у вас есть объект user, у которого 5 атрибутов - Ф, И, О, дата рождения и пол. Если у вас поменялась информация о пользователе №5, например изменилась фамилия - и вы вызовете метод PUT /users/5, и передадите в теле запроса только фамилию, то на выходе у вас останется объект user с id = 5, и фамилией = тому, что вы передали в запросе. Все остальные атрибуты затрутся. Поэтому для обновления необходимо передавать все объект целиком, включая те атрибуты, которые не менялись.
Если же вы вызовете метод PATCH /users/5 с таким же запросом, то у вас обновится только фамилия, остальной объект останется не тронутым.
Логичный вопрос - а зачем тогда вообще использовать PUT? Ответ достаточно простой - он намного проще в реализации. Куда проще передать объект целиком ценой нескольких байт трафика и подменить его, чем обновлять каждый атрибут по отдельности, маппить их и т.д. Особенно если у вас какой-нибудь огромный объект, типа "Заявка на кредит", у которой под тысячу атрибутов, а вам нужно обновить 200 из них.
Тут разработчики могут меня поправить, но объясняли мне в свое время так.
Удаляет конкретный ресурс по-указанному URI.
Интересное: на самом деле нет никаких проблем с тем, чтобы заставить метод GET создавать какой-нибудь ресурс или заставить метод DELETE обновлять. Т.е. это не технические ограничение, это "лишь" концептуальная идеология того, как правильно (и для чего) использовать различные методы.
Чтобы на всех проектах, все участники разработки были в едином контексте. И когда вы будете видеть какой-нибудь метод, типа POST /loanApplication//offers - вы явно поймете, что это метод предназначенный для добавления новых офферов конкретной заявке на кредит.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.
Всем привет.
Сегодня рассмотрим такой важный протокол, как HTTP. Важный потому, что именно его используют в качестве протокола передачи данных современные технологии интеграции (REST, gRPC).
HTTP расшифровывается как HyperText Transfer Protocol, «протокол передачи гипертекста». Изначально этот протокол использовался для передачи гипертекстовых документов в формате HTML. Сегодня он используется для передачи произвольных данных - c помощью него можно передавать хоть JSON, хоть XML.
В основе HTTP - клиент-серверная структура передачи данных․ Клиент формирует запрос (request) и отправляет на сервер; на сервере запрос обрабатывается, формируется ответ (response) и передается клиенту.
HTTP не шифрует передаваемую информацию. Для защиты передаваемых данных используется расширение HTTPS (Hyper Text Transfer Protocol Secure), которое “упаковывает” передаваемые данные в криптографический протокол SSL или TLS. Но это совсем другая история)
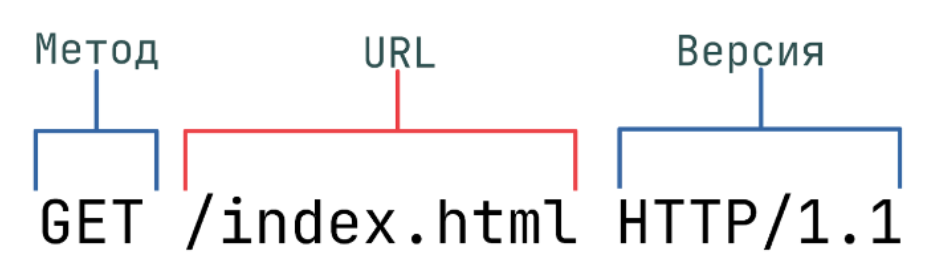
HTTP запрос состоит из трех основных частей: строка запроса (request line), заголовок (message header) и тело сообщения (entity body). Тело сообщения не является обязательным параметром. Между заголовком и телом есть пустая разделительная строка.
В строке запроса указывается:
Метод – название запроса (определяет действие), одно слово из стандартного списка, заглавными буквами;
URI определяет путь к запрашиваемому ресурсу;
Версия – пара разделённых точкой цифр. Например: 1.0.
Пример HTTP запроса:
Заголовок запроса добавляет некоторую дополнительную информацию к сообщению запроса, которое состоит из пар «имя / значение», по одной паре на строку, а имя и значение разделяются двоеточием.
Обычно в заголовках передается какая-либо мета информация. Например, токен.
Последней частью запроса является его тело. Оно бывает не у всех запросов: запросы, собирающие (fetching) ресурсы, такие как GET, HEAD, DELETE, или OPTIONS, в нем обычно не нуждаются и тела запроса у них быть не должно (так реализовать метод можно, но это не правильно).
В то же время для методов POST, PUT, PATCH - тело использовать можно и нужно.
Структура ответа, в целом, идентична структуре запроса. Также есть строка статуса, заголовок и тело.
Стартовая строка ответа HTTP, называемая строкой статуса, содержит следующую информацию:
Пример строки статуса: HTTP/1.1 404 Not Found.
Более подробно про коды состояния и как их использовать расскажу как-нибудь в другой раз.
Пример ответа:
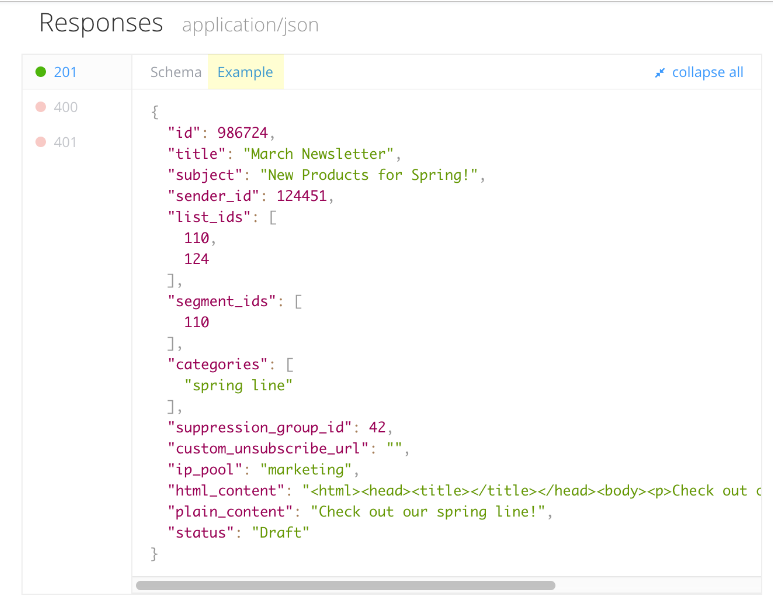
Заголовки ответов HTTP имеют ту же структуру, что и все остальные заголовки: не зависящая от регистра строка, завершаемая двоеточием (':') и значение, структура которого определяется типом заголовка. Весь заголовок, включая значение, представляет собой одну строку.
Тело присутствует не у всех ответов. Например, если мы вызываем метод DELETE, чтобы удалить какую-либо сущность, то в ответ нам вернется лишь строка статуса с HTTP-кодом 204.
Как правило тело ответа используется в том случае, когда нам нужно вернуть вызывающей стороне информацию о ресурсе. Например, если мы вызываем метод GET /users/25, то в ответе вернется полная информация о пользователе с идентификатором = 25.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.P.S.: Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.
Вот я тут ночь не спала, потому что глобальная несправедливость на свете творится. Вру, конечно, ночью я дрыхла совершенно замечательно, но про несправедливость - чистая правда.
Тут такая история случилась: выложила я очередной пост про секс-игрушку, попался он на глаза @Dr.PerryCox и человек от души, но вполне культурно комментарий написал. На Пикабу ведь как бывает - пост выложишь и отвлечёшься на пятнадцать минут. Возвращаешься, а там уже пепелище, развалины дымятся, пикабушники друг другу головы пооткусывали и тебе заодно глаз подбили. Профилактически, чтобы не забывал, кто тут главный.
А тут всё в рамках приличия - высказал человек своё мнение, мы в обычном порядке немного сцепились, но Пикабу и не такое видал. Я честно, пропустила момент, когда история получила продолжение, потому что комментарии @Dr.PerryCox исчезли и по его словам он получил эцих с гвоздями бан от модераторов сообщества NSFW Познавательный.
В общем ужас, катастрофа, мы все умрём и теория мирового заговора со мной во главе, как с главным зачинщиком всех глобальных катаклизмов. Спорить не буду, иногда побыть мировым злом, это знаете ли, даже льстит. Но тут-то я момент упустила по невнимательности и всё мимо прошло, пару дымовых шашек в комментариях кинула и отвлеклась.
Но ничего не пропадает бесследно, потому что скриншоты комментариев у @Dr.PerryCox уцелели и были выложены в пост о глобальной несправедливости. Чему я изумилась повторно, именно в этот момент узнав, что хозяйское добро пропало, человек теперь в бане и вообще обидно.
Так вот, вопрос в студию - в какое Спортлото писать, чтобы человеку вернули его комментарий и вынули @Dr.PerryCox из эциха? , NSFW Познавательный, можно вернуть всё как было? Если по уставу оптом нельзя, то хотя бы комментарий ему назад отдайте, а то сидит человек, расстраивается.
P.S. Если что, я запомнила, кто на меня модераторам ябедничал. )
Всем привет.
Сегодня продолжим погружаться в системный анализ, в его техническую часть.
Перед тем как начать изучать REST, API и все что с этим связано - нужно изучить, хотя бы верхнеуровнево, архитектуру, на базе которой строятся все современные приложения. Для этого рассмотрим клиент-серверную архитектуру.
Архитектура «клиент-сервер» определяет общие принципы организации взаимодействия в сети, где имеются серверы, узлы-поставщики некоторых специфичных функций (сервисов) и клиенты, потребители этих функций.
В клиент-серверной архитектуре одним из основных вопросов является вопрос о том, как разделить клиентов и серверы. Так, приложения типа клиент-сервер разделяют на три уровня:
уровень представления - на уровне представления обеспечивается взаимодействие с пользователем приложения с помощью пользовательского интерфейса. Его основное предназначение состоит в отображении информации (все формочки, кнопочки и т.д.) и получении информации от пользователя. Этот уровень может работать в веб-браузере или как графический пользовательский интерфейс компьютерного или мобильного приложения.
уровень бизнес-логики - центральное звено приложения, на котором реализованы все основные функции системы. Обрабатывается вся информация, собранная на уровне представления согласно бизнес-правилам для выполнения конкретных бизнес-целей системы. Кроме того, уровень приложения может добавлять, изменять и удалять данные, расположенные на уровне данных;
уровень данных - функции управления ресурсами. На данный момент в современных приложениях его роль зачастую выполняет реляционная (или нереляционная) система управления базами данных.
Т.е. система реализована таким образом, что собирает всю ту информацию, которую пользователь ввел на интерфейсном уровне, затем передает ее на уровень бизнес-логики, каким-то образом обрабатывает с учетом всех бизнес-правил и затем либо возвращает обогащенную информацию обратно, либо сохраняет ее в базу.
Клиент-серверная архитектура делится на двухзвенную и трехзвенную.
Двухзвенная архитектура
Двухзвенной (two-tier, 2-tier) она называется из-за необходимости распределения трех базовых компонентов между двумя узлами (клиентом и сервером). Двухзвенная архитектура используется в клиент-серверных системах, где сервер отвечает на клиентские запросы напрямую и в полном объеме, при этом используя только собственные ресурсы. Т.е. сервер не вызывает сторонние сетевые приложения и не обращается к сторонним ресурсам для выполнения какой-либо части запроса.
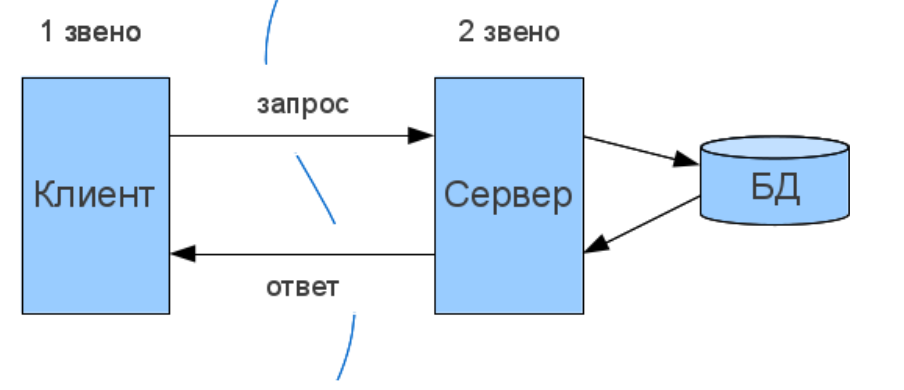
В двухзвенной клиент-серверной архитектуре используется так называемый «толстый» клиент, который выполняет отображение информации и обработку всех данных (порядка 80 % всех работ). Сервер осуществляет только хранение и предоставление данных (порядка 20 % работ).
Толстый клиент - это когда приложение напрямую запущено через условный .exe файл на вашем компьютере и работает в отдельном окне (всякие ERP\WMS системы, те же клиенты 1С и пр. не облачные штуки). Собственно их основной минус в том, что т.к. нет выделенного сервера - все функции реализуются на уровне клиента, который потребляет только те ресурсы, которые доступны компьютеру, на котором это приложение установлено.
А большинство офисных компьютеров, как известно, не отличаются большой производительностью, поэтому необходимость сформировать условный отчет даже из относительно небольшого количества данных заставляет их сильно задуматься. Это если не говорить о необходимость формировать или отображать какие-нибудь таблицы, состоящие из нескольких миллионов строк.
Трехзвенная архитектура
Собственно именно эти недостатки в большей степени послужили толчком к появлению трёхзвенной клиент-серверной архитектуры с отдельно выделенным сервером приложений.
Выглядит это всё схематично следующим образом:
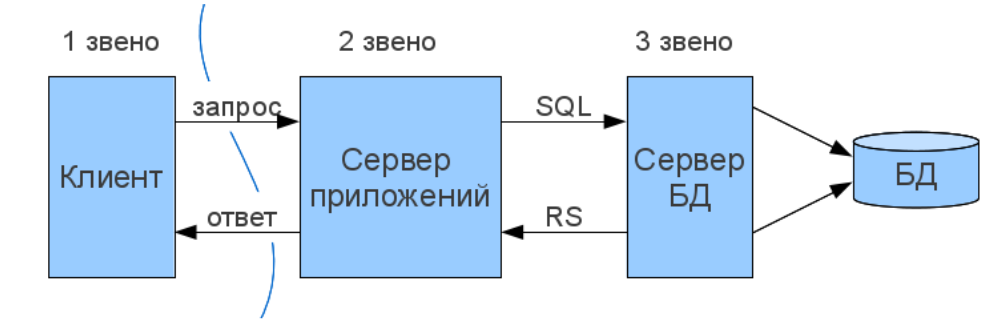
Также в этой архитектуре мы уже можем позволить себе использовать "тонкий клиент", т.е. просто страницу в вашем веб-браузере или мобильное приложение. И с учетом этого, мы просто обязаны вынести из него всю логику (даже простейшую валидацию желательно перенести на уровень бизнес-логики, либо, как минимум, дублировать), потому что у него не остается почти никаких ресурсов для ее выполнения.
Всё, на что способен тонкий клиент - это отображать интерфейс, взаимодействовать с пользователем, посылать запросы на сервер по любому чиху и обрабатывать ответы от него. Ну и иногда, по мере какой-то острой необходимости, горящих сроков или чего-то в этом духе можно запихнуть в него какую-то логику, но стараемся этого избежать.
Но при этом мы получаем монструозный (в плане его мощностей) сервер, который способ обслуживать огромное количество клиентов одновременно, в многопоточном режиме обработки данных и выполнять необходимую бизнес-логику за какие-то доли секунд, даже при большом объем данных.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.S. Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.
Всем привет.
Сегодня вернемся немного назад. Если про сами требования мы уже поговорили, про то, что это вообще такое, какими они бывают и какими качествами обладают, то вот про то, а как вообще их собирать - еще не проговорили.
Для этого придумали и сформулировали не мало методологий - давайте в них разберемся.
Интервью - это один из самых базовых и понятных способов сбора требований. Казалось бы, что в этом такого - просто взял заказчика под руку, отвел его в сторону и как давай спрашивать про всё подряд. Но тут кроются определенные тонкости.
Вообще, если говорить прям по теории-теории, то перед тем, как начать интервьюировать - надо определиться с теми лицами, которым нужно задавать вопросы.
Выглядит это так, что сначала нужно сформировать полный перечень заинтересованных лиц и потенциальных (или уже текущих) пользователей системы (тут важно понимать, что цели реальных пользователей системы могут сильно отличаться от целей бизнес-заказчиков, т.к. именно им работать с системой, а не заказчикам). Из каждой группы выделить одного или двух специалистов, чтобы избежать однобокого взгляда на проблему.
После этого уже требуется согласовать календарь встреч и желательно заложить время сразу на повторное интервью, обязательно заложив время между ними для того, чтобы вы могли осмыслить те ответы, которые вам были даны.
Это что касается теории. Однако на практике - в большинстве случаев это уже устарело, потому что у вас, почти всегда, будет ровно одна точка входа в бизнес-требования в виде PO или просто выделенного человека, достаточно высокой должности (уровня зам или руководителя определенного направления компании), которые сами ответят вам на все вопросы, без привлечения толпы лиц. И именно этот человек будет тем самым рупором, через который идет трансляция целей бизнеса на команду разработки.
Другой подход может быть, если вы внедряете какую-нибудь ERP\WMS систему на какое-нибудь предприятие, в этом случае я готов поверить, что та самая базовая теория будет актуальна для такого случая.
Пара важных моментов:
Всегда готовьтесь к интервью. Я не знаю почему, но даже опытные аналитики это не всегда делают, к моему сожалению. Не должно быть такого, что вы приходите на встречу, вам предлагают начать диалог и задавать вопросы, а вы такой: "Ой, да я даже не знаю, давайте вы расскажете просто что вам нужно". Очень желательно, заранее подготовить список вопросов или просто понять концепцию разговора, т.к. именно вы должны быть его драйвером.
Это нормально, когда после интервью у вас появляется больше вопросов, чем ответов - в этом случае, необходимо взять определенное время на проработку информации и потом собрать следующую встречу. Повторять до тех пор, пока не наступит достигните желаемой степени определенности в задаче.
Еще один распространенный и интересный подход - это первичное создание прототипов системы. Прототип - это модель, позволяющая продемонстрировать интерфейс или поведение проектируемой системы. Сбор и уточнение требований прототипированием гораздо эффективнее проводить после выявления первичных требований любым другим способом, как минимум потому, что люди в большинстве своём визуалы и не особо готовы воспринимать большие полотна текста (как этот пост), но достаточно легко готовы идти на контакт и общаться, если вы показываете им картинки.
Тут важно понимать, что необходимо создать прототип, который отражает идеи реализации, близкие пользователям и заказчикам, которые они высказали при первичном обсуждении. Это поможет замотивировать их еще активнее вовлекаться в процесс диалога.
Прототип может быть:
Статическим, показывающим положение элементов в интерфейсе или структуры данных;
Динамическим - с возможностью демонстрации поведения системы по наступлению определенных событий;
Интерактивным - позволяющим пользователям и участникам заинтересованных сторон выполнять реальные действия так, как это будет работать в разрабатываемой системе.
Но у такого подхода есть и ряд минусов:
Сильно увеличивает трудозатраты, особенно если не удастся переиспользовать интерфейс для экономии времени разработки, т.к. стоит понимать, что сам процесс прототипирования отнимает достаточно большое количество времени, если это не на салфетке на встрече нарисованный макет интерфейса;
Заказчики могут акцентировать фокус своего внимания на красоту и дизайн прототипа их системы вместо обсуждения действительно важных вопросов реализации. Поэтому важно постоянно уводить нить их рассуждения от "Блин, тут кнопка не в наших корпоративных цветах, надо это поправить", к обсуждению того, как эта кнопка должна работать и что должно происходить по ее нажатию.
Не менее основной подход к выявлению требований (особенно для системного аналитика), чем интервью, в случае если у заказчика уже есть какая-то система (или несколько), которые вам нужно доработать.
Данный подход выполняет сразу несколько целей:
Сократит время последующего анализа потребностей и проблем заказчика. Кроме этого облегчит взаимодействие с заказчиком и другими членами команды разработки, т.к. вы больше вникните в процесс и будете разговаривать на одном языке;
Возможно вы сможете получить ту информацию, которой уже (или еще) из представителей заказчика не обладает.
Для начала требуется определить с какой документацией необходимо и желательно работать. Это можно сделать у представителя заказчика, который может предоставить нам список необходимой “литературы”, релевантной относительно текущих процессов. Либо, если вам предоставили доступ к каким-либо информационным ресурсам заказчика - поискать такие документы самостоятельно.
Мозговой штурм - наверно это метод, про который слышали все. Но как его правильно применять? Обычно, рекомендуется его использовать среди команды или в связке с командой и заказчиком, в случае, если нужно определить первичный набор идей.
Такой формат не позволит вам выбрать что-то наилучшее или оптимальное, однако позволит по накопившимся идеям получить быструю обратную связь, отследить реакцию заказчика на них, выбрать несколько наиболее подходящих и далее “копать” в том направлении, развивая эти идеи.
Перед тем как проводить такой штурм, в любом случае требуется определить цель. Без чёткой цели идеи будут предлагаться уж совсем несуразные. Возможно, вам будет весело, но вот продуктивно ли? Сомневаюсь.
Однако в процессе фонтанирования идеями нельзя сразу отбрасывать даже самые безумные и фантастичные на первый взгляд идеи. Как показывает практика, некоторые из них при более детальном рассмотрении оказывается совсем уж не сумасшедшими, а вполне даже дельными и гениальными.
И еще один принцип работы с таким подходом - ни в коем случае нельзя критиковать возникающие идеи, т.к. после этого человек, подвергнутый критике, вряд ли будет предлагать другие идеи (да, да, в IT люди очень нежные в большинстве своем). Просто в определенный момент, когда закончится поток идей - уже записанные идеи должны быть оценены, возможно проведением голосования и в следующий этап перейдут только наиболее популярные идеи.
Кроме всех вышеперечисленных способов - можно применить еще один, достаточно интересный. Если вы не разрабатываете что-то совсем новое и уникальное, не делаете “rocket science”, то скорее всего у вашего продукта или системы уже есть аналоги. И очень не глупой идеей будет проанализировать их, посмотреть на отзывы пользователей, самому попользоваться данной системой (если это возможно) и сделать на основании этого выводы о преимуществах и недостатках данного продукта.
И конечно же, чтобы не натыкаться на те же грабли - заранее исправить недостатки, которые уже не нравятся пользователям и позаимствовать удачные и интересные решения, которые каким-либо образом можно использовать в вашем продукте.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
P.S. Также веду телеграмм-канал, в котором делюсь разным про профессию и про свой путь в ней. Есть и хардовая информация (асинхронные, синхронные интеграции, примеры ТЗ\шаблонов написания микросервисов), так и более софтовая - см. закрепленный дайджест.
Всем привет.
Сегодня продолжим наш экскурс в глубины системного анализа. Перед тем, как мы перейдем к интеграциям - логично было бы поговорить об XML\JSON.
XML, в переводе с англ eXtensible Markup Language — расширяемый язык разметки. Используется для хранения и передачи данных. Отличается простотой синтаксиса и универсальностью. XML позволяет описывать документы с помощью тегов, которые можно задавать самостоятельно. Так что увидеть его использование можно и в API в том числе (хотя и намного реже, чем JSON).
XML позволяет:
записывать иерархию — «один подчиняется другому»;
размечать текст по смыслу от важного к второстепенному;
хранить типовые данные — скрипты, настройки программ, названия чего-либо;
размечать текст для машинного обучения;
хранить результаты работы текстовых редакторов.
У XML-файлов древовидная структура. Это значит, что в них используется набор тегов, внутри которых могут находиться другие теги со своими значениями. Самый верхнеуровневый узел называется корнем, а все, что находится внизу, — листьями.
В XML каждый элемент должен быть заключен в теги. Тег — это некий текст, обернутый в угловые скобки:
<tag>
Текст внутри угловых скобок — название тега.
Тега всегда два:
Открывающий — текст внутри угловых скобок
<tag>
Закрывающий — тот же текст (это важно!), но добавляется символ «/»
</tag>
С помощью тегов мы показываем системе «вот тут начинается элемент, а вот тут заканчивается».
В любом XML-документе есть корневой элемент. Это тег, с которого документ начинается, и которым заканчивается. Он показывает начало и конец нашего запроса, не более того. А вот внутри уже идет тело документа.
Для примера давайте опишем объект Task нашей системы (см. первую практику) в формате XML.
<task type="issue"> (открывающий тег и корневой элемент заодно)
<topic> Не работает принтер</topic>
<priority> high</priority>
<isMass> false </isMass>
<description> Сломался принятер. Выключился ибольше не включается. Нужно срочно распечатать много документов, а не получается. Что делать? Просьба помочь</description>
</task> (закрывающая тег)
Пара особенностей, помимо перечисленных:
Все теги являются регистро-чувствительными. Это значит, что если, например, тег <user> закрыт </User>, документ будет оформлен некорректно;
Значения атрибутов должны быть заключены в кавычки. Атрибут — характеристика тега. Любые теги могут иметь атрибуты;
Вложенность тегов контролируется, поэтому важно следить за порядком открывающих и закрывающих тегов.
JSON (англ. JavaScript Object Notation) — текстовый формат обмена данными, основанный на JavaScript. Но при этом формат независим от JS и может использоваться в любом языке программирования.
JSON обладает рядом преимуществ. К ним относят:
компактность;
простое чтение предложений, написанных подобным образом – актуально и для машины, и для человека;
легкость преобразования в структуры данных для разнообразных языков программирования;
наличие у большинства языков программирования функций и библиотек, которые помогут создавать и читать структуры JSON.
JSON-объект — это неупорядоченное множество пар «ключ:значение», которые разделены ",".
Давайте теперь тот же объект Task опишем в формате JSON и я думаю, что на этом примере сразу станет понятна структура, потому что она намного более простая и наглядная, чем XML
{ (открывающая скобка - начало объекта, закрывающая скобка - конец объекта)
"type" : "issue", (Слева - ключ, справа - значение)
"topic" : "Не работает принтер",
"priority" : "high",
"isMass" : "false",
"description" : "Сломался принятер. Выключился ибольше не включается. Нужно срочно распечатать много документов, а не получается. Что делать? Просьба помочь"
}
JSON на данный момент наиболее распространен и повсеместно используется в REST, например.
P.S.: По традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.
В следующей части расскажу базовую теорию про интеграцию и начнем плавно переходить к REST'у.
Всем привет.
Сегодня поговорим о таком прикладном инструменте системного аналитика, как UML.
Зачастую у многих возникает вопрос - а зачем вообще рисовать любые диаграммы и схемы? Мы все такие замечательные, уже научились писать требования, оформлять разными способами (даже красивыми) - в общем-то, по этим требованиям же и так всё понятно?
И отчасти это так. Глобально - качественно собранных и поставленных требований к системе за глаза хватает для того, чтобы система была нормально разработана, без каких-либо проблем. Но зачем останавливать себя в желании "прибраться" в голове или наглядно объяснить что-нибудь команде - ведь наличие наглядной схемы позволяет решить все эти задачи и заметно упрощает жизнь.
Это я подвожу к тому, что если у тебя есть свободное время на создание схемы (а это бывает не так часто), то лучше ее сделать. А возможно и в целом начать аналитику именно с нее. Это поможет структурировать твои собственные мысли, увидеть возможные неточности или не проработанные моменты в том или ином процессе.
UML – унифицированный язык моделирования (Unified Modeling Language) – это система обозначений, которую можно применять для объектно-ориентированного анализа и проектирования. Его можно использовать для визуализации, спецификации, конструирования и документирования систем.
UML использует в основном графические обозначения для выражения дизайна проектов. Использование UML помогает проектным группам лучше взаимодействовать между собой и легче вникать в проекты.
Основные цели дизайна UML:
Предоставить пользователям готовый, выразительный язык визуального моделирования, чтобы они могли разрабатывать и обмениваться осмысленными моделями;
Быть независимым от конкретных языков программирования и процессов разработки (важно);
Обеспечить формальную основу для понимания языка моделирования;
Поддержка высокоуровневых концепций разработки, таких как совместная работа, структуры, шаблоны и компоненты.
Преимущества и недостатки проектирования диаграмм:
Начнем с недостатков:
Дополнительная трата времени, которого может и не быть;
Необходимость знать и понимать различные нотации.
Преимущества:
Возможность посмотреть на задачу с разных точек зрения;
Другим членам команды (включая заказчиков) легче понять суть задачи и способ ее реализации;
Диаграммы сравнительно просты для чтения после достаточно быстрого ознакомления с их синтаксисом.
В UML диаграммы подразделяют на два типа — это структурные диаграммы и диаграммы поведения.
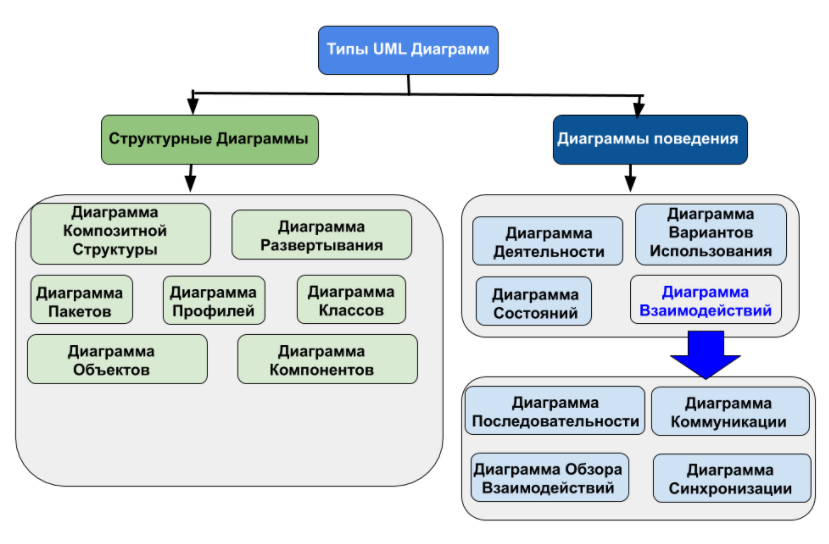
Структурные диаграммы показывают статическую структуру системы и ее частей на разных уровнях абстракции и реализации, а также их взаимосвязь. Элементы в структурной диаграмме представляют значимые понятия системы и могут включать в себя абстрактные, реальные концепции и концепции реализации. Существует семь типов структурных диаграмм:
Диаграмма составной структуры
Диаграмма развертывания
Диаграмма пакетов
Диаграмма профилей
Диаграмма классов
Диаграмма объектов
Диаграмма компонентов
Диаграммы поведения показывают динамическое поведение объектов в системе, которое можно описать, как серию изменений в системе с течением времени. А к диаграммам поведения относятся:
Диаграмма деятельности
Диаграмма прецедентов
Диаграмма состояний
Диаграмма последовательности
Диаграмма коммуникаций
Диаграмма обзора взаимодействия
Временная диаграмма
Все мы рассматривать не будем (при желании это можно сделать самостоятельно) - разберем лишь основные, которые наиболее часто используются (по крайней мере в моей практике).
Диаграмма классов — это центральная методика моделирования, которая используется практически во всех объектно-ориентированных методах. Эта диаграмма описывает типы объектов в системе и различные виды статических отношений, которые существуют между ними.
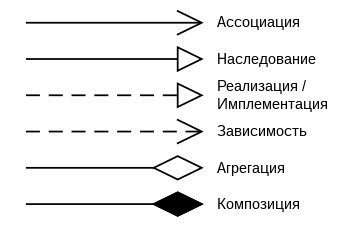
Три наиболее важных типа отношений в диаграммах классов (на самом деле их больше), это:
Ассоциация - представляет отношения между экземплярами типов. Например, человек работает на компанию, у компании есть несколько офисов;
Зависимость — это форма отношения использования, при которой изменение в одном классе - влечёт за собой изменение другого, причём обратное не обязательно.
Агрегация - это ассоциация типа «целое-часть». При этом обе части могут жить отдельно друг от друга (машина - колесо).
Композиция – это такая агрегация, где объекты-части не могут существовать сами по себе (дом - комната).
Пример:
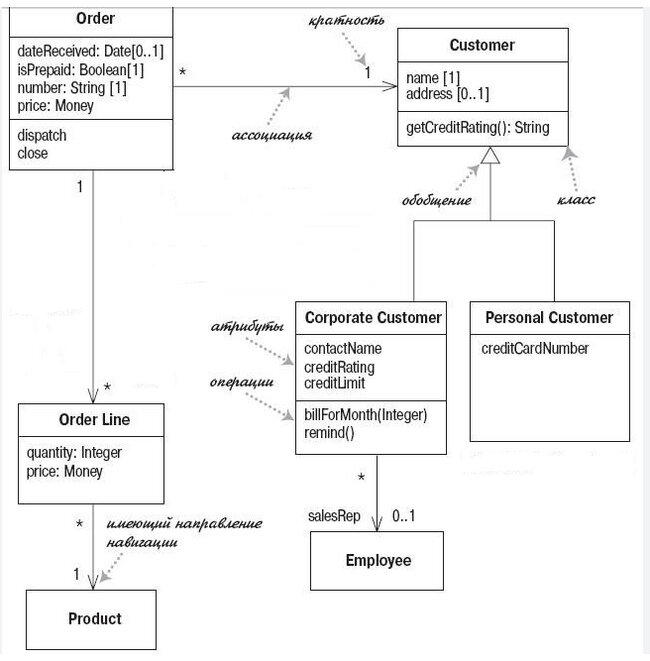
Стоит еще рассказать про такую вещь как "Кратность". По сути между объектами может быть всего 3 типа кратности, которые уже могут варьироваться:
1 к 1. Это значит, что ровно одному объекту соответствует ровно один объект. Например - у одного человека может быть только один паспорт (не берем загранник);
1 ко многим. Одному объекту может соответствовать множество объектов (множество это может быть и 0). Например - один автор написал много книг;
Многие ко многим. Множеству объектов может соответствовать множество других объектов. Например - много поставщиков поставляют много товаров (в том числе пересекающихся).
При этом могут быть частные варианты, такие как, как 1 : 0..* (1 объекту соответствует множество объектов или ни одного. Например, у одного покупателя может быть множество заказов, но их может и не быть совсем). Или 1 : 3..*, т.е. одному объекту соответствует минимум три других и в целом любые возможные комбинации.
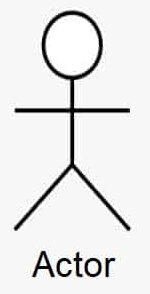
Диаграмма прецедентов - описывает функциональные требования системы с точки зрения того, как она будет использоваться людьми и/или взаимодействовать с другими системами.
Сущности, с которыми система должна взаимодействовать, называются actor’ами (эктор, актер), при этом каждый из них ожидает, что система будет вести себя строго определенным образом.
Актер - если упростить, то это какой-то конкретный пользователь или роль, или другая система, подсистема или класс.
Другой участник данный диаграммы - прецедент. Это описание отдельного аспекта поведения системы с точки зрения пользователя (да, это те самые UC, которые рассматривали в прошлой части).
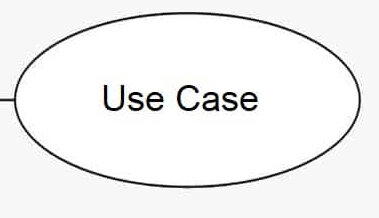
Прецеденты и актеры соединяются с помощью линий. Часто на одном из концов линии изображают стрелку, причем направлена она к тому, у кого запрашивают сервис, другими словами, чьими услугами пользуются. Прецеденты могут включать другие прецеденты, расширяться ими, наследоваться и т. д.
Пример диаграммы:

В языке UML несколько стандартизированных видов отношений между актерами и вариантами использования:
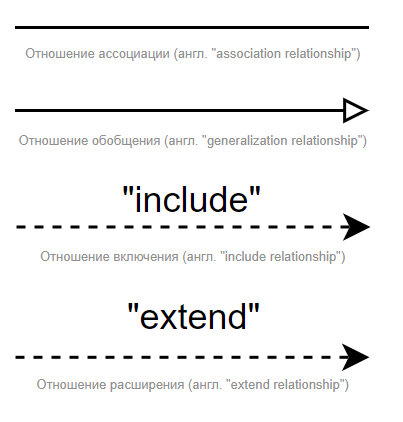
Отношение ассоциации - самая обычная закрашенная стрелочка, которой можно соединять только актера и варианты использования. Она означает, что актер может выполнять действия, описанные вариантом использования.
Отношения обобщения - показывает, что определенный актёр или вариант использования может быть обобщён до другого актёра или варианта использования. Как на примере выше - UC "открытие счета ФЛ" и "открытие счета ФЛ" обобщены в UC "Открыть счет".
Отношение включения - показывает, что включенный UC должен быть обязательно выполнен, при выполнении другого варианта использования, в который он входит.

Например, при предоставлении кредита в банке всегда происходит проверка платежеспособности клиента.
Отношение расширения - показывает, что расширенный UC может быть выполнен в составе того UC, в который он входит, а может и не выполняться. Обязательности уже нет.

Например, при предоставлении кредита в банке может происходить с предоставлением налоговых льгот, при определенных условиях, но это не обязательно.
Диаграмма состояний - это тип диаграммы, используемый в UML для описания всех состояний системы и переходов между ними. Она отображает разрешенные состояния и переходы, а также события, которые влияют на эти переходы. Кроме этого помогает визуализировать весь жизненный цикл объектов и, таким образом, помогает лучше понять системы, основанные на состоянии.
Другими словами - такая диаграмма показывает то, как сущность переходит из одного состояния в другое.
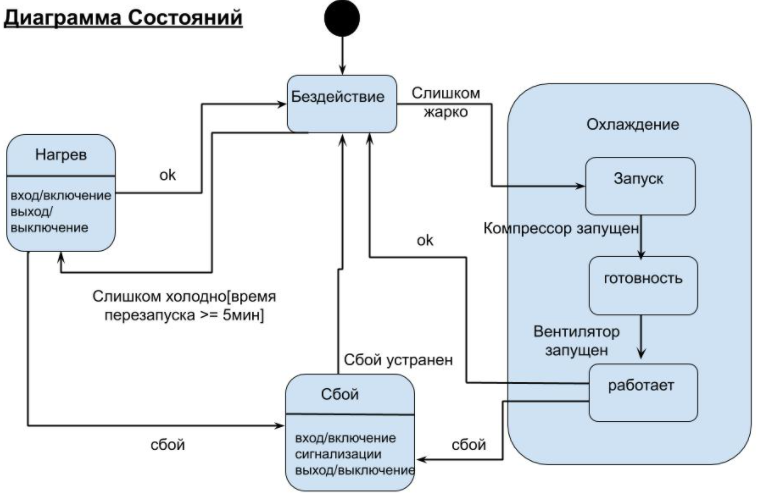
На самом деле очень интересный тип диаграммы и их неплохо использовать для определения статусной модели ваших сущностей, для того, чтобы спроектировать какие у них могут быть статусы и при каких условиях они будут в эти статусы переходить.
Если рассматривать схему из примера, то это работает примерно так:
Стартовый статус нашей системы = "Бездействие". Дальше, если срабатывает триггер (допустим, получаем сообщение от датчика температуры, что она превысила установленную норму) - то система начинает переходить к общему статусу "Охлаждение". Он в свою очередь состоит из нескольких процессов - запуск компрессора, готовность и работа вентилятора.
Система находится в этом состоянии, до тех пор пока снова не срабатывает определенный триггер, например - получение сигнала от датчика температуры о том, что она вернулась в норму. В этом случае вентиляторы останавливаются и система снова переходит в статус = "Бездействие".
Или, например, случился сбой - система перешла в соответствующее состояние и, допустим, не может выйти из него без ручного вмешательства техника.
Могу из своего опыта сказать, что диаграммы очень важны на проекте и желательно, чтобы при его документировании они использовались. Потому что одно дело бросить взгляд на диаграмму, прочитать ее и понять что происходит в нужном тебе процессе, другое дело вчитываться в пространное ТЗ с техническими подробностями, которые тебе, возможно, сейчас и не нужны.
Плюс, многие разработчики очень просят, чтобы диаграммы добавлялись в ТЗ, потому что им так намного проще осознавать что нужно сделать и что за чем идет (особенно актуально для интеграций). Да и в целом большинство людей визуалы.
P.S. Про UML это еще не всё, но пост получается очень большим, поэтому разобью на две части и добью остаток про UML в следующей. Заодно там же начну рассказывать про BPMN.
P.P.S: Завтра (25.02.2023 в 12.00 московского времени) у меня в телеграмме пройдет эфир где я буду отвечать на разные вопросы про карьеру/профессию/перспективы/развитие и т.д. В общем на все вопросы, которые мне будут задавать участники эфира.
Ничего продавать не буду, поэтому если хотите поболтать\послушать или даже есть какие-то вопросы на указанные темы - приходите, буду рад всем. Ссылка на телеграмм в моем профиле.
Всем привет.
Сегодня у нас небольшая практика и мы продолжим дополнять "ТЗ" нашей ITSM-системы сценариями использования и пользовательскими историями, которые рассмотрели в прошлом посте.
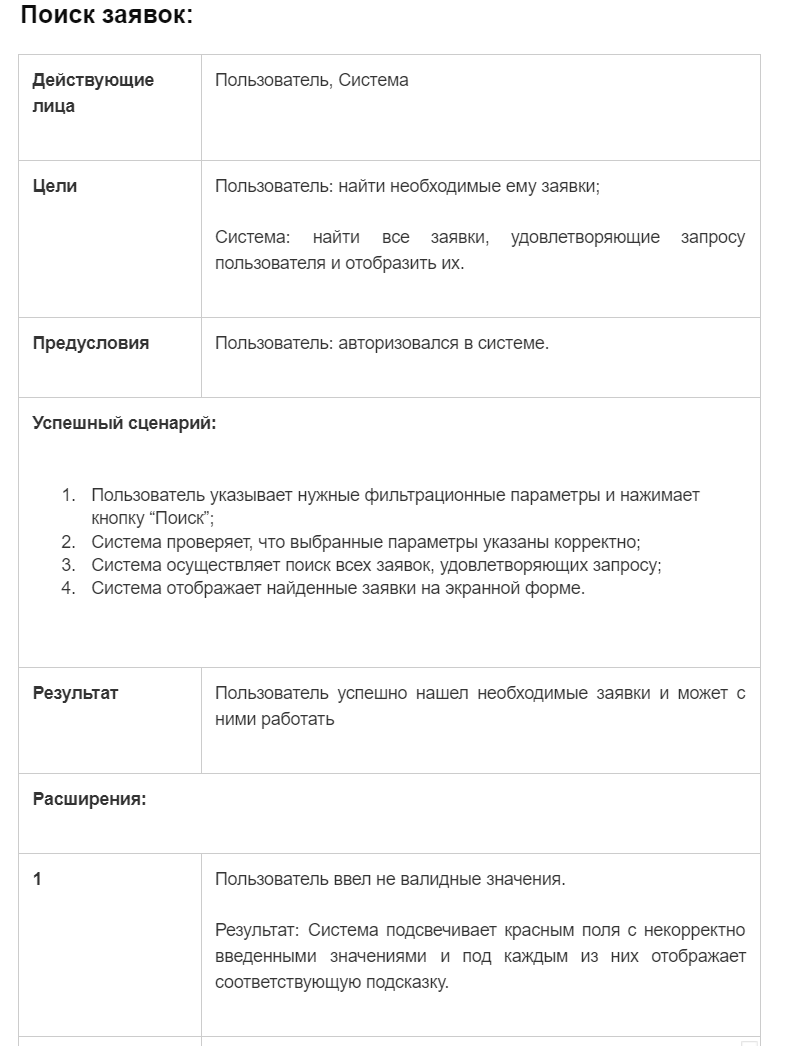

Второй:


Итого, с помощью этих двух UC мы покрыли те же самые функции, которые мы описывали в первой части практики. Само собой, это получилось менее детально и продуманно, потому что сам формат этого не подразумевает.
Однако, для верхнеуровневых требований он вполне подход (и для согласования с заказчиками в том числе).
Как пользователь, я хочу иметь возможность отменять ранее созданные заявки, если проблема потеряла актуальность;
Как пользователь, я хочу изменять приоритет заявки;
Как сотрудник поддержки, я хочу иметь возможность перевести заявку на другую рабочую группу, если проблема вне моей зоне ответственности;
Как руководитель, я хочу иметь возможность выгружать отчет по своем отделу в разрезе сотрудников, чтобы отслеживать их эффективность;
Как заказчик услуг, я хочу иметь возможность просматривать статистику вовремя закрытых заявок в разрезе отделов поддержки, чтобы отслеживать их попадание в SLA;
Как пользователь, я хочу иметь несколько быстрых фильтров, выбрав один из которых - я смогу найти сразу все заявки из нужной категории;
Как пользователь, я хочу иметь возможность вернуть заявку обратно в работу, если меня не устроило предлагаемое решение.
P.S.: Думаю, что еще 2-3 поста займет рассказ про различным инструменты необходимые системному аналитику и после этого можно будет уже наконец перейти к самой мякотке - интеграциям.
P.P.S: Уже по традиции - буду признателен за вопросы про карьеру\профессию\чему угодно связанному со сферой IT - постараюсь ответить на всё.

